SemGraph
Give LLMs a High-Level Semantic Understanding of Any Codebase
Developers can get answers to broad questions about a codebase, revealing how code components connect and interact to form high-level features.
SemGraph (short for “Semantic Graph”) is a technology that provides Large Language Models with a bird’s-eye view of a codebase structure by mapping code entities and their relationships as a graph and providing a way for an LLM to query that graph. This gives LLMs a deeper, more unified perspective on how everything fits together. By using this semantic approach, LLMs can understand high-level architecture across multiple languages, allowing them to answer broader questions - like how the entire payment flow works across different layers, without the need to manually sift through endless files.
Key Pain Points Faced by Modern Dev Teams
Siloed Understanding Across Large Codebases
- Developers often waste time manually searching or reading countless files to understand how everything fits together.
- Traditional code search tools don’t provide the bigger picture across languages and services.
Limits with Existing AI/LLM Integrations
- Large Language Models can only handle limited context at once.
- Without a structured way to query code relationships, LLM answers might be incomplete or inaccurate.
- Embedding codebase data into a model can be costly, slow, and require expensive hardware.
Complex Cross-Language Integrations
- Modern applications use multiple languages, making it tough to see relationships between front-end, back-end, and APIs.
- Existing tools can struggle to unify these pieces into a single view.
Risky Refactoring & Maintenance
- Even small changes can break parts of the system if developers miss hidden dependencies.
- It’s easy to overlook related code in a large project when planning updates or fixes.
Slow Onboarding & Knowledge Transfer
- New team members take longer to grasp high-level architecture.
- Documenting everything by hand is time-consuming and quickly goes out-of-date.
The Promise
- Structured Code Insights: SemGraph provides a clear, explicit structure that enables LLMs to understand how features span multiple files or services.
- Efficient and Real-Time: It operates without requiring embeddings or model fine-tuning, with the codebase graph updating immediately as source files change.
- Token-Efficient Comprehension: By utilizing the codebase graph, LLMs can grasp high-level structures without reading entire code files, conserving tokens and enhancing performance.
- LLM Imperfection Mitigation: By using an explicit graph representation, SemGraph helps mitigate issues like LLM hallucinations and problems related to lossy compression in LLMs.
- Multi-Language and External IntegrationBemGraph supports defining relationships across code segments written in different languages and with external services, offering a unified view of complex, heterogeneous systems.
Core Architecture
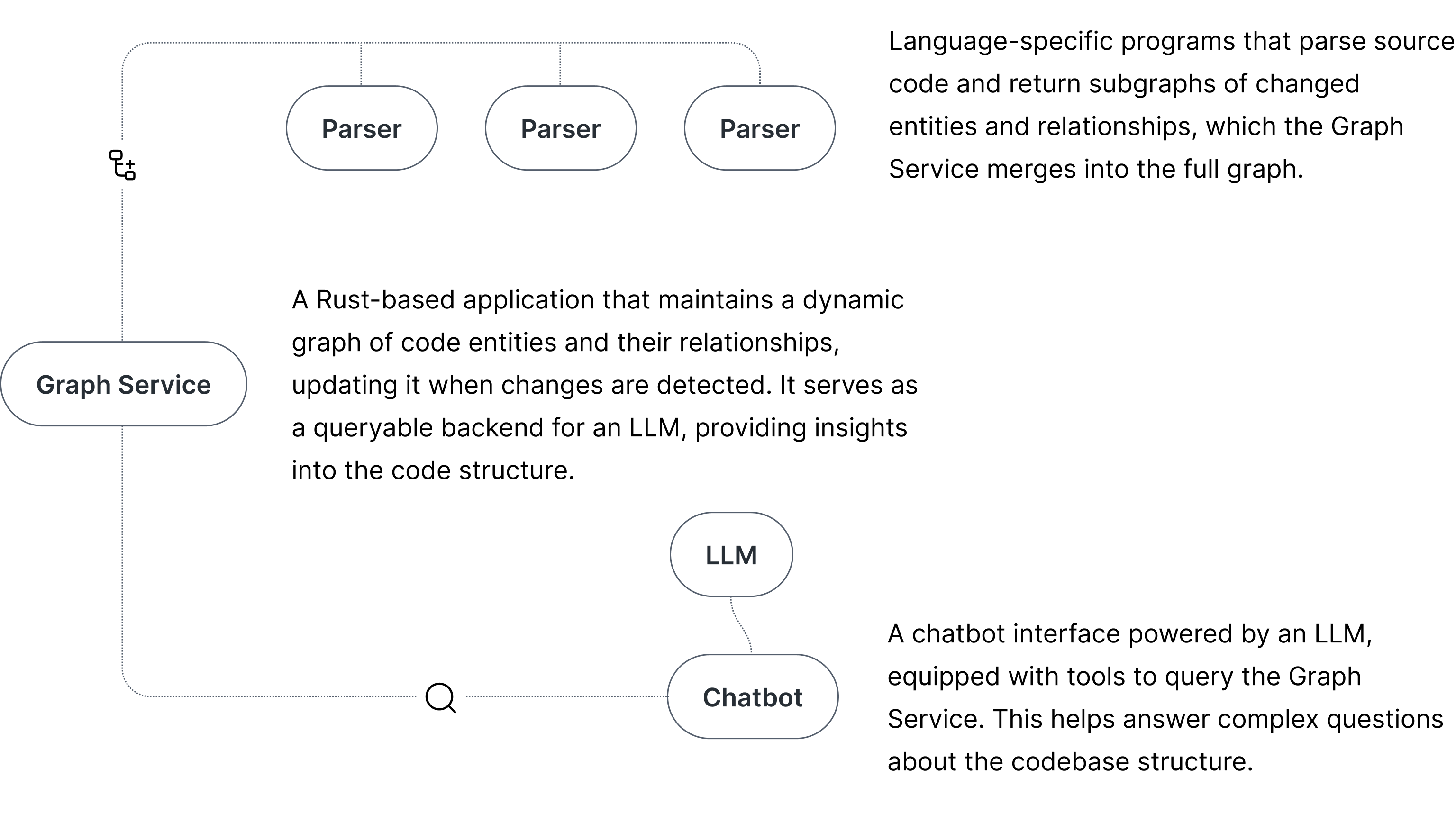
The Graph Service, parsers, and chatbot can run locally on a developer’s machine or on a server hosting the codebase.
Core Advantages
Other known approaches to enhance LLM code understanding require
loading code into context windows or creating vector representations
through embeddings. All of these are expensive in terms of token
consumption and computational resources.
SemGraph offers foundational advantages through its graph-based
approach. The graph provides a language-agnostic representation of a
codebase, which can be deterministically queried by an LLM. This
allows LLMs to extract specific information about the codebase
efficiently, improving both accuracy and performance.
Deep Dive
Graph Service
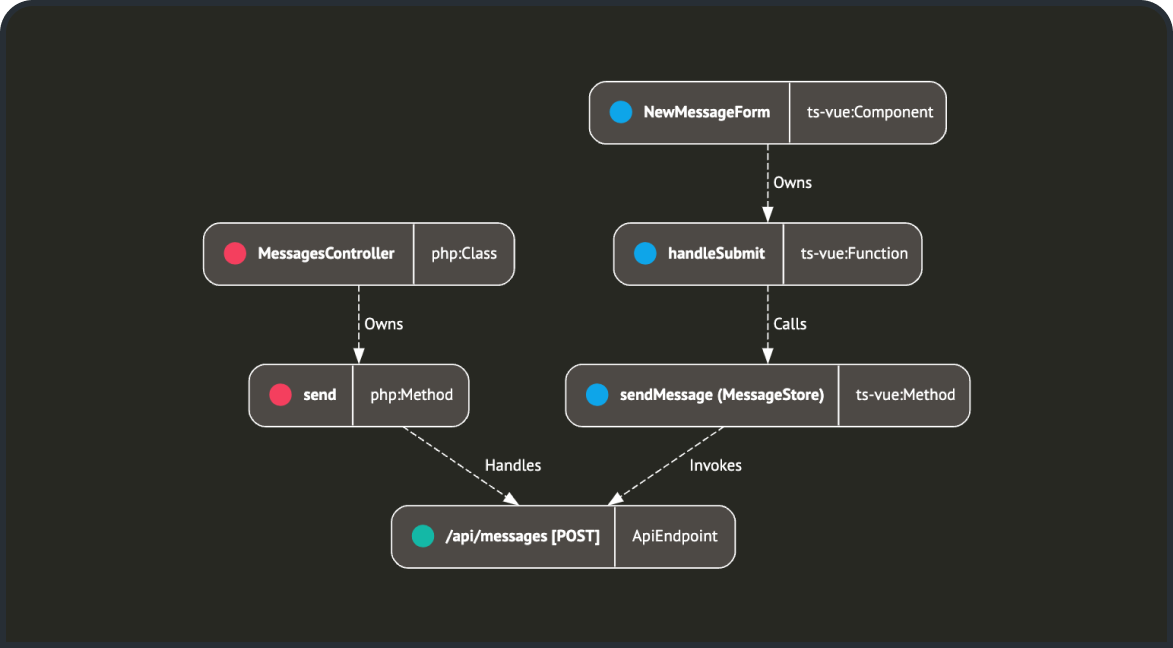
Graph Service maintains a graph of nodes and edges. Each node
represents a codebase entity, such as a class or a function. Edges
capture relationships between these entities, for example “Owns”
or “Invokes.”
The Graph Service updates the entire
graph whenever it detects changes in the code—without the lengthy
tokenization or embedding steps often associated with LLM-based
approaches. This means an LLM can access fresh structural data as
soon as the code changes.
The types of nodes and edges are determined by a language. In
object-oriented languages, for instance, the language parser can
define “class” or “method” nodes, along with “inherits” or
“implements” edges. For TypeScript, the parser can include a
“Type” node type.
A codebase can have multiple associated parsers, defined in a
SemGraph configuration file and mapped to specific file
extensions. The graph service monitors the codebase for changes
and, when changes are detected, it invokes the appropriate
parser(s) for the updated files.
Parsers generate a subgraph for the changed entities. The graph
service then merges this subgraph into the main graph, creating,
updating, or deleting nodes and edges as necessary to keep the
graph in sync with the latest codebase state.
The graph service can be queried through a TCP/IP API. One key
query is “describe,” which tells the LLM what kinds of entities
and edges exist in the codebase. Another essential feature is the
ability to find paths between nodes, showing how different parts
of the codebase are connected.
Parsers
A parser is a separate program invoked by the graph service. Its
purpose is to convert code entities and relationships into a graph
representation. Typically, a parser can be written in the same
language it handles (e.g., PHP for PHP, TypeScript for
TypeScript), making use of third-party libraries that generate
ASTs and simplify parser development.
Once the AST is generated, the parser traverses it and creates
corresponding graph nodes and edges. These nodes and edges are
returned as JSON and then used by the Graph Service as a subgraph.
Chatbot
The Chatbot receives prompts from the user and forwards them to the LLM. It includes a set of tools that the LLM can use to query the Graph Service through LLM function calls. The sample chatbot is implemented with Python on the server side and TypeScript/Vue on the client side, illustrating how SemGraph can be integrated into an application. The same principles apply to any other application that needs to leverage SemGraph for code analysis or similar tasks.
Implementation Status
Graph Service
Functional alpha stage:
implements most of the required functionality and is backed by
comprehensive unit tests covering its core operations. Provides a
stable foundation for further development and iterative
refinement.
Future potential: there is
likely a broader range of query types that could enhance LLM
understanding of the codebase, which should be identified and
implemented. Additionally, there is room to further optimize both
graph merging and querying operations to improve overall
performance.
Parsers
Working prototype demo the
included PHP and TypeScript/Vue parsers effectively demonstrate
the approach for different languages, showing how language-native
parsers can be used to generate subgraphs compatible with the
Graph Service.
Future potential custom nodes
and edges, like API endpoints, should currently be defined by
developers. Detecting them in ASTs for popular frameworks like
Laravel should not be difficult. Perhaps an LLM could assist with
this - an endpoint can be identified through static code analysis,
and the corresponding piece of code can then be sent to the LLM
for further analysis.
Chatbot Back-end (Python)
A working foundation that integrates a remote LLM API with the Graph Service endpoints. The backend is designed with modularity in mind, allowing it to be ported to other frameworks or extended with additional capabilities. It defines tools for querying the LLM, which can be further refined or expanded as needed.
Chatbot Front-end (TypeScript/Vue)
Demo prototype illustrates how the technology can be embedded into a product, featuring graph visualization and the ability to output streamed Markdown and code blocks.
Insights & Ideas
LLM Selection
During development, I tested various LLMs and found that OpenAI's
The
current implementation relies on system instructions and tool
descriptions. Fine-tuning function calling could further improve
the tool's accuracy.
Other Ideas
I see great potential in features that SemGraph and the chat interface could implement to make AI assistance more valuable for developers. Some ideas:
- Use .semgraph files to provide text-based instructions to LLMs, enabling them to follow predefined guidelines when executing various tasks. For example, these files could include instructions on a team’s established unit testing approach.
- Create tools that can trace and safely refactor code in large codebases, even across multiple languages and layers.
- With SemGraph, fully automated code writing becomes more feasible, as an up-to-date representation of the codebase updates instantly with every change.
 Watch the Demo
Watch the Demo